Build on DeskDay your way: Public API and MCP support is now live and available for early access. Request access
When a user can’t log in, their laptop won’t connect to the network, or a critical business application goes dark, the clock starts ticking. How quickly and effectively your IT team responds in that moment isn’t just a function of skill. It’s a function of structure.
Tiered IT support is one of the most foundational and often underappreciated frameworks in IT service management. At its core, it’s a simple idea: not every problem requires the same expertise, and not every engineer should be spending their time on every problem. But building a tiered support model that actually works in practice requires a deeper understanding of what each level is designed to do, where one tier ends, and another begins, and how the handoffs between them are managed.
This guide covers everything you need to know about IT support levels from L0 through L4 and why the structure you build around them determines the quality of IT service your organization delivers.
Before diving into the levels themselves, it’s worth grounding the conversation in why tiered support exists in the first place.
IT environments generate a vast and highly varied stream of support requests. On any given day, a help desk might receive requests for password resets, printer issues, VPN configuration problems, application bugs, server performance degradation, and network failures, all in the same queue. These issues are not equivalent. They differ enormously in complexity, urgency, and the expertise required to resolve them.
Without a tiered structure, one of two things tends to happen. Either every ticket lands with a generalist pool, and complex issues take too long to resolve because no one has the right depth of expertise. Or specialized engineers get pulled into low-complexity, high-volume work, burning capacity that should be reserved for critical issues.
A well-designed tiered model solves both problems simultaneously. It ensures routine issues are resolved quickly and cheaply at lower levels, while complex and critical issues are routed immediately to the people best equipped to handle them. The result is faster resolution across the board, better resource utilization, and a support experience that scales with organizational growth.
Downtime is expensive. Research consistently puts the cost of IT downtime in the range of thousands of dollars per minute for larger organizations. A tiered support model is, in no small part, a risk mitigation strategy.
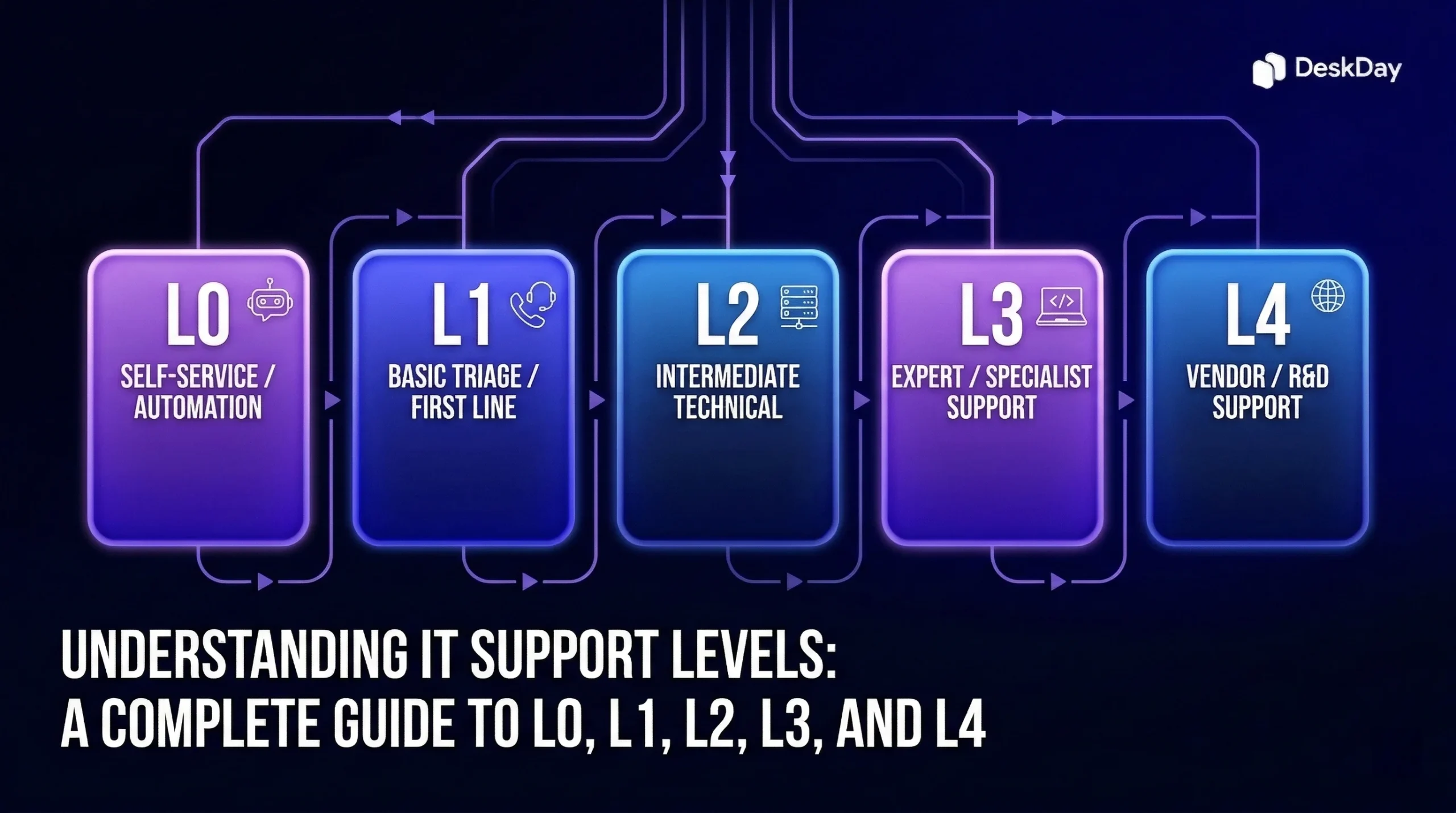
The first tier in the support model isn’t staffed by humans at all. L0 is the self-service layer, the collection of tools, resources, and automated systems that allow users to resolve issues on their own, without ever submitting a ticket.
L0 typically includes:
The philosophy behind L0 is straightforward: a significant portion of support demand is driven by the same set of recurring, well-understood issues. If those issues can be addressed through accessible, well-maintained self-service content, they never need to become tickets. The L0 layer intercepts high-frequency, low-complexity demand before it enters the support queue at all.
When L0 is built and maintained well, the impact is substantial. Ticket deflection rates climb, L1 agents have more time for genuinely complex issues, and users get faster resolution, often instantaneously, without waiting in a queue.
The challenge with L0 is that it requires ongoing investment. Knowledge bases go stale. Chatbots misfire. FAQs don’t keep pace with product or process changes. Organizations that build L0 and treat it as a one-time effort find that it degrades quickly, and users stop trusting it. L0 means that users can’t rely on generates more tickets than no L0 at all, because frustrated users submit requests the moment they hit a dead end.
Critical design principle: L0 should never be a dead end. When self-service fails, the transition into L1, via a ticket form, live chat, or clear escalation prompt, should be frictionless. Users who feel trapped in a self-service loop that isn’t working will become your most frustrated callers.
L1 is where human support begins. These are the first agents a user reaches when self-service isn’t enough, the frontline of the help desk.
L1 technicians handle high-volume, well-defined issues that can typically be resolved in a single interaction. Common L1 responsibilities include:
L1 agents work primarily from documented runbooks, SOPs, and knowledge base references. Their value isn’t deep technical expertise; it’s speed, communication, and the ability to correctly assess what they can solve versus what needs to move up. A strong L1 team with good documentation and tooling can resolve anywhere from 30 to 60 percent of all incoming tickets at this tier, depending on the nature of the environment.
One of the most important and undervalued functions of L1 is quality triage. When an L1 agent escalates a ticket, the completeness and accuracy of the context they pass along directly determine how quickly L2 or L3 can resolve it. Poorly triaged tickets, missing logs, unclear issue descriptions, and incomplete user information create unnecessary rework at higher tiers. Training L1 agents not just in technical basics but in disciplined documentation and communication is one of the highest-leverage investments an IT leader can make.
The First Contact Resolution (FCR) rate is the primary metric for L1 performance. A high FCR rate means issues are being resolved where they enter the system, which is both the most efficient and the most satisfying outcome for the user. Improving FCR at L1 is usually a function of two levers: better training and better knowledge management.
When an issue exceeds the scope of L1, requiring deeper investigation, system-level access, or specialized product knowledge, it escalates to L2.
L2 technicians occupy the middle ground of the support hierarchy. They’re experienced, technically sophisticated professionals who can move beyond scripted troubleshooting and conduct genuine root cause analysis. They are not typically the people who designed the systems they’re supporting, but they understand those systems at a level that enables meaningful diagnosis and resolution.
Typical L2 responsibilities include:
One of the defining characteristics of L2 is that issues handled here are often less well-defined at the point of entry. L1 works from known problems with known solutions. L2 frequently encounters issues where the cause isn’t immediately obvious, where investigation is required before resolution is even possible. This demands not just technical depth but analytical thinking and methodical problem-solving.
The escalation handoff from L1 to L2 is a critical juncture in the support flow. For L2 to be effective, escalations need to arrive with complete context: what the user reported, what L1 tried, what didn’t work, and any relevant logs or error codes. Without this, L2 wastes time re-investigating ground already covered, a common source of inefficiency in organizations that haven’t formalized their escalation documentation standards.
SLA design matters here. L2 SLAs should not mirror L1 SLAs. Issues at this tier require deeper investigation and often involve cross-team coordination. Setting unrealistic response or resolution targets for L2 drives behavior that undermines quality; agents rush to close tickets rather than properly diagnosing them.
L3 is the highest internal tier in the support structure. It’s staffed by subject matter experts, senior engineers, architects, and in many cases, the developers or product engineers who built the systems being supported.
L3 is engaged when an issue is complex enough that it requires deep system knowledge, code-level investigation, or architectural context that only subject matter experts possess. This tier handles problems that are, by definition, not in the runbook.
Core L3 responsibilities include:
A key characteristic of L3 work is that its outputs should flow back down the support hierarchy. When an L3 engineer resolves a novel issue, that resolution, properly documented, becomes an L2 or L1 resource. Over time, a well-functioning support organization gets progressively better at handling a wider range of issues at lower tiers, because L3 consistently feeds its knowledge back into the system.
Organizations that don’t formalize this knowledge-transfer loop find their L3 teams repeatedly solving the same issues that should have been addressed at L2 or L1 months earlier. The cost isn’t just efficiency; it’s the opportunity cost of senior engineering time spent on problems that should have been solved further down the chain.
L3 is also the tier where post-incident reviews carry the most organizational value. When a major incident is resolved, the L3 analysis of what happened, why it happened, and what structural or procedural changes will prevent recurrence is among the most valuable work the team can do. Organizations that treat post-incident review as a checkbox exercise, rather than a genuine learning mechanism, are leaving significant resilience and efficiency gains on the table.
L4 represents the boundary between your internal support structure and the outside world. It’s the tier engaged when an issue requires capabilities, access, or proprietary knowledge that your internal teams simply don’t have.
L4 typically involves:
L4 is not a tier you escalate to lightly. Vendor engagement introduces variables outside your control, response time commitments that depend on support contract tier, vendor capacity, and the complexity of the issue. This makes the L4 escalation process design critically important.
Before escalating to L4, L3 teams should prepare a structured escalation package: reproduction steps, environment details, logs, impact assessment, and documented internal investigation steps. Vendors who receive well-organized escalations respond faster and more accurately. Organizations that escalate with poor IT documentation find themselves going in circles, re-explaining the issue, answering questions that should have been preempted, and losing time.
Managing vendor relationships at the L4 tier is also a strategic function, not just an operational one. Enterprise support contracts with major vendors often include SLA guarantees, named technical account managers, and priority response lanes. Organizations that treat vendor relationship management as a procurement exercise rather than an ongoing operational partnership tend to get slower, lower-quality support when they need it most.
Defining the tiers is necessary but not sufficient. The connective tissue of a tiered support model, the escalation pathways between levels, is where the model either delivers on its promise or breaks down.
Effective escalation has three components:
Clear criteria. Every agent at every tier should know, without ambiguity, what conditions trigger escalation. Time-based escalation triggers (if unresolved after X minutes/hours, escalate automatically) are a useful safeguard, but they should complement, not replace,judgment-based escalation criteria grounded in issue complexity and impact.
Complete context transfer. Every escalation should carry the full context of what has already been tried and what has been learned. This means structured ticket documentation standards, not free-text notes that vary in completeness based on individual agent habits. Templates, required fields, and mandatory documentation checkpoints enforce consistency.
Feedback loops. Information should flow back down the escalation chain as well as up. When L3 resolves an issue, L1 and L2 should understand what the resolution was and why it worked. When L4 vendors identify a systemic product defect, the internal teams who escalated should be debriefed so they can manage user communication and adjust their own troubleshooting approaches.
For organizations looking to build or strengthen their tiered support structure, a few principles consistently separate high-performing implementations from those that stagnate:
Define ownership, not just tiers. A tier isn’t a box on an org chart; it’s a scope of responsibility. Every tier needs clear definitions of what it owns, what it doesn’t own, and what conditions move work out of its hands. Ambiguity in ownership is the single most common source of tickets falling through the cracks.
Invest in knowledge management as infrastructure. The knowledge base underpins every tier. L0 depends on it for self-service. L1 depends on it for consistent, scripted resolution. L2 and L3 depend on it for the institutional context. Organizations that treat the knowledge base as a documentation project rather than a living operational system find it degrades faster than it’s built.
Set tier-appropriate SLAs. One of the most common mistakes in tiered support design is applying uniform SLA targets across all tiers. The work at each tier is fundamentally different in nature and complexity. L1 can and should be measured on tight response and resolution windows. L3 investigations into complex infrastructure failures require a different time horizon. Applying the same targets to both tiers either creates impossible expectations for L3 or allows L1 to operate more slowly than it should.
Build continuous training into the model. Support work evolves constantly, new technologies, new products, and new failure modes. A tiered support model that is well-calibrated today will drift out of calibration over time if training isn’t treated as an ongoing operational function. The best teams run regular knowledge reviews, conduct post-incident training updates, and use ticket data to identify emerging patterns that warrant new SOPs or knowledge base content.
Measure what matters at each tier. FCR at L1. Mean Time to Escalate and escalation quality scores at L1 and L2. Root Cause Identification Rate and knowledge contribution at L3. Vendor SLA adherence at L4. The right metrics are tier-specific; organisations that apply a single performance dashboard across all levels miss the nuanced signals that indicate where the model is working and where it isn’t.
It’s worth noting that tiered support is a framework, not a rigid formula that every organization must implement identically. Smaller IT teams may combine L1 and L2 functions into a single group of generalist-leaning technicians. Organizations with narrow, specialized products may have very thin L1 and very deep L3 functions. Managed service providers may run the full L0 through L4 model across dozens of client environments simultaneously.
The details of implementation should reflect organizational context: the nature of the technology being supported, the size and composition of the team, the volume and type of support demand, and the maturity of the existing support processes.
What doesn’t vary across contexts is the underlying logic: match issue complexity to the right level of expertise, route efficiently, document thoroughly, and build feedback loops that make the entire structure smarter over time.
Tiered IT support is one of those operational fundamentals that tends to get taken for granted until it breaks. When escalation pathways are unclear, when tickets get routed to the wrong tier, when knowledge isn’t transferred between levels, the symptoms show up as slow resolution times, frustrated users, and overloaded engineers. By the time the problem is visible, it has usually been building for a while.
IT support levels are a structured way of organizing technical support teams based on the complexity of issues they handle. Each level focuses on different types of problems, helping organizations resolve issues efficiently and escalate complex cases to specialists when needed.
Managed Service Providers (MSPs) often structure their support teams using these levels to manage large volumes of client requests. This helps them deliver faster response times and maintain service quality across multiple customers.
Automation and AI tools can handle many L0 and some L1 tasks, such as answering common questions or guiding users through troubleshooting steps. However, complex technical issues still require human expertise at higher support levels.
A tiered support model improves efficiency by ensuring that:
1. Simple issues are resolved quickly
2. Technical experts focus on complex problems
3. Support teams use their time and skills more effectively
When an issue cannot be resolved at one level, it is escalated to the next level with additional context and diagnostics. This ensures that simple issues are handled quickly while complex problems reach the right specialists.

Get exclusive content on the MSP industry and become a part of the DeskDay community.